1. 简介
Redis hash 是一个string类型的field和value的映射表,hash特别适合用于存储对象。 Redis 中每个 hash 可以存储 232 - 1 键值对(40多亿)
可以看成具有KEY和VALUE的MAP容器,该类型非常适合于存储值对象的信息,
如:uname,upass,age等。该类型的数据仅占用很少的磁盘空间(相比于JSON)
2. Hash命令
赋值语法:
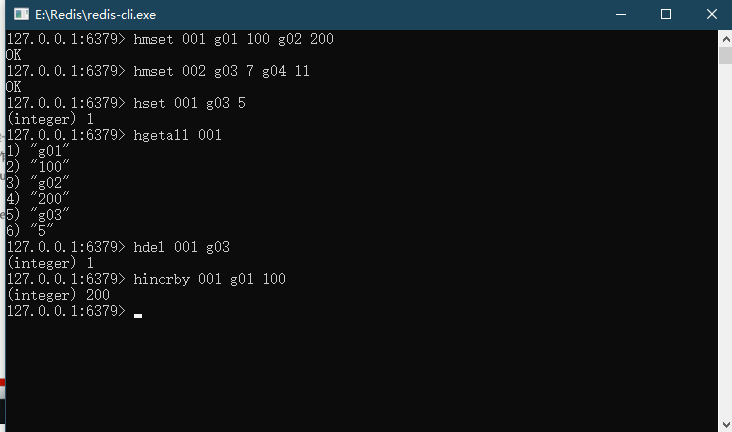
1 | HSET KEY FIELD VALUE |
为指定的KEY,设定FILD/VALUE
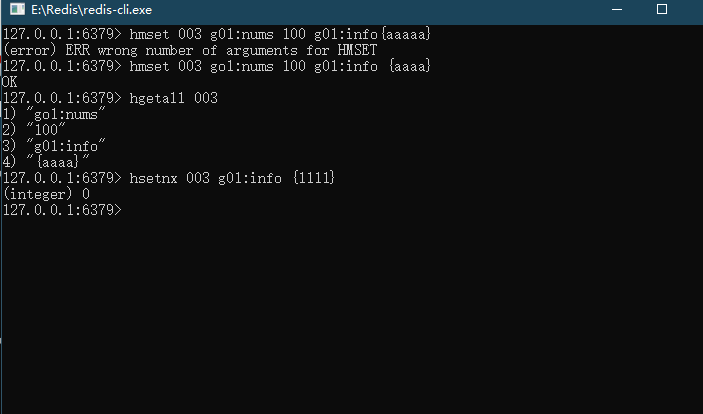
1 | HMSET KEY FIELD VALUE [FIELD1,VALUE1] |
同时将多个 field-value (域-值)对设置到哈希表 key 中。
取值语法:
1 | HGET KEY FIELD |
获取存储在HASH中的值,根据FIELD得到VALUE
1 | HMGET key field[field1] |
获取key所有给定字段的值
1 | HGETALL key |
返回HASH表中所有的字段和值
1 | HKEYS key |
获取所有哈希表中的字段
1 | HLEN key |
获取哈希表中字段的数量
删除语法:
1 | HDEL KEY field1[field2] |
删除一个或多个HASH表字段
其它语法:
1 | HSETNX key field value |
只有在字段 field 不存在时,设置哈希表字段的值
1 | HINCRBY key field increment |
为哈希表 key 中的指定字段的整数值加上增量 increment 。
1 | HINCRBYFLOAT key field increment |
为哈希表 key 中的指定字段的浮点数值加上增量 increment 。
1 | HEXISTS key field |
查看哈希表 key 中,指定的字段是否存在
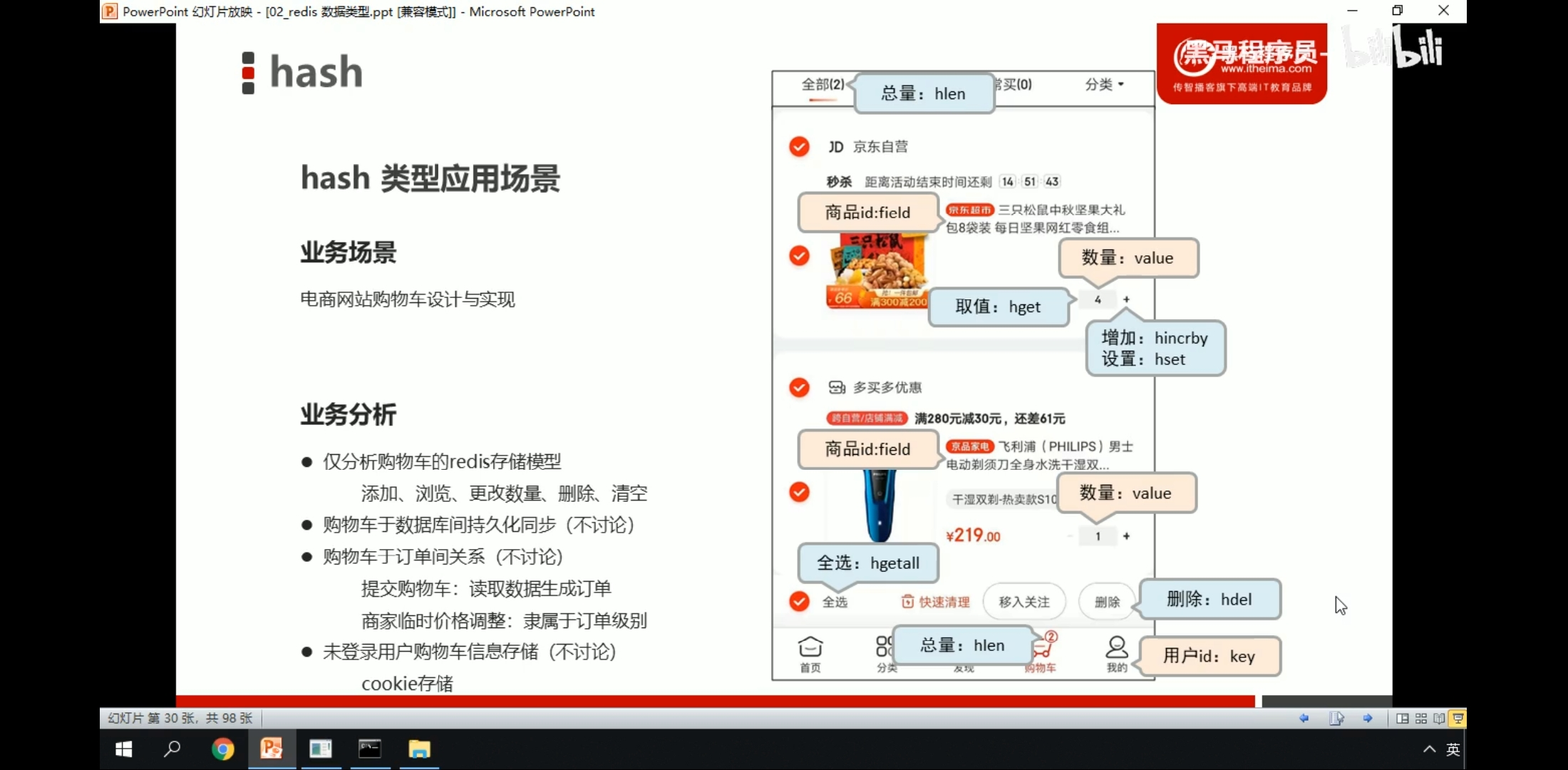
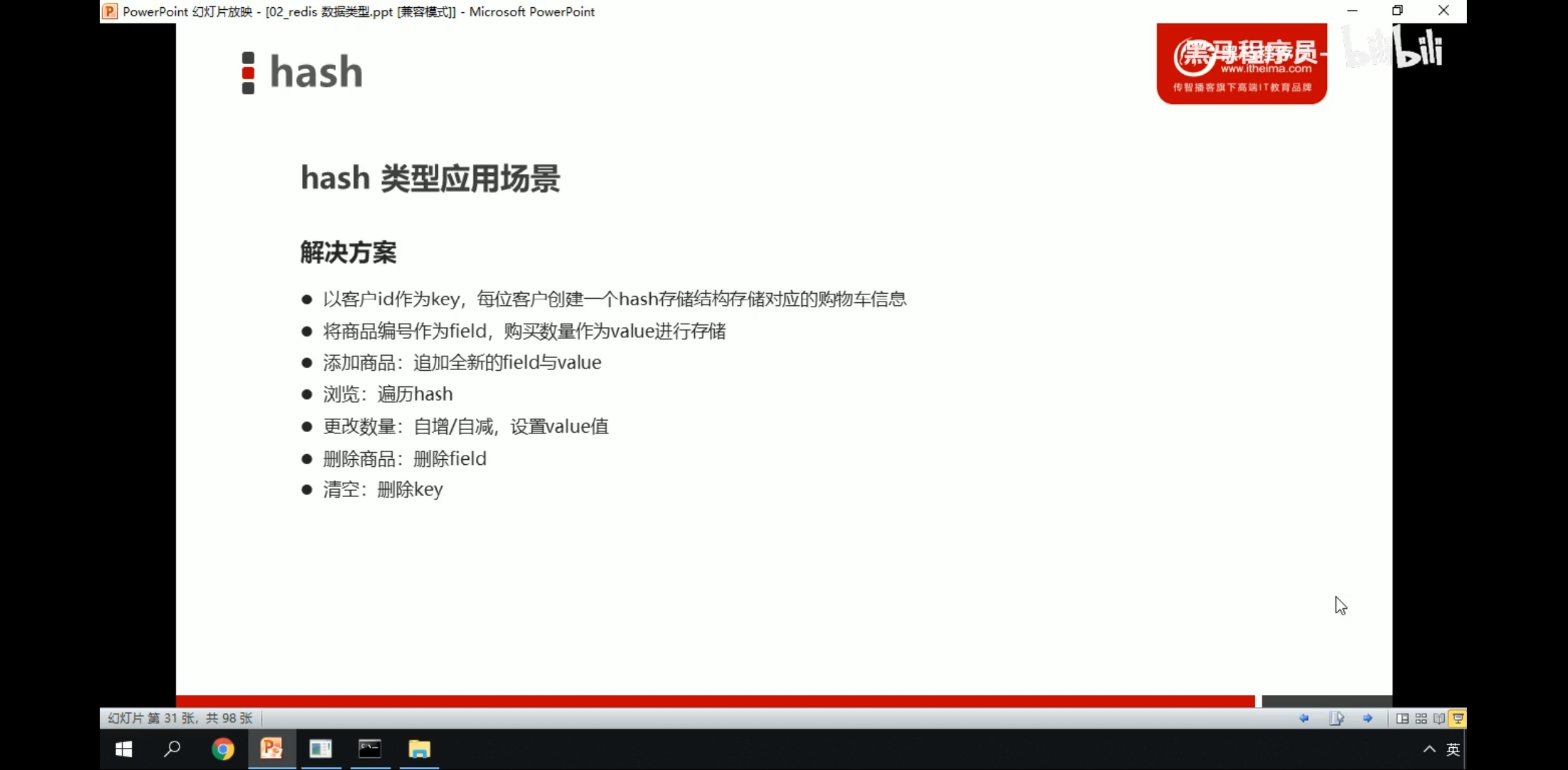
3.应用场景
Hash的应用场景:(存储一个用户信息对象数据)
1、 常用于存储一个对象
2、 为什么不用string存储一个对象?
hash是最接近关系数据库结构的数据类型,可以将数据库一条记录或程序中一个对象转换成hashmap存放在redis中。
用户ID为查找的key,存储的value用户对象包含姓名,年龄,生日等信息,如果用普通的key/value结构来存储,主要有以下2种存储方式:
第一种方式将用户ID作为查找key,把其他信息封装成一个对象以序列化的方式存储,这种方式的缺点是,增加了序列化/反序列化的开销,并且在需要修改其中一项信息时,需要把整个对象取回,并且修改操作需要对并发进行保护,引入CAS等复杂问题。
第二种方法是这个用户信息对象有多少成员就存成多少个key-value对儿,用用户ID+对应属性的名称作为唯一标识来取得对应属性的值,虽然省去了序列化开销和并发问题,但是用户ID为重复存储,如果存在大量这样的数据,内存浪费还是非常可观的。
总结:
Redis提供的Hash很好的解决了这个问题,Redis的Hash实际是内部存储的Value为一个HashMap,并提供了直接存取这个Map成员的接口
4.应用场景