首先推荐一个学习数据结构的网站
https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
索引的本质
索引是帮助MySQL高效获取数据的排好序的数据结构
索引数据结构
- 二叉排序树
- 红黑树
- Hash表
- B-Tree(数据库用的)
在这里说一下为什么不用二叉树,如果你的数据是排序过的例如1,2,3,4,5,6
那么插入到二叉树情况如图:
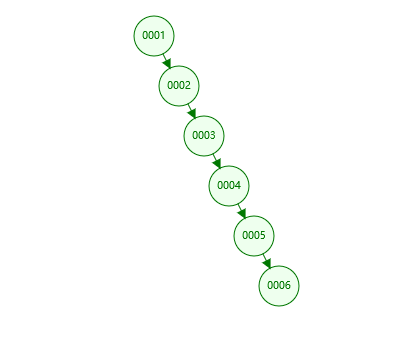
很明显这样是根本无法帮助你快速查询。
至于红黑树, 是一种自平衡二叉搜索树,接下来我会用图片演示,
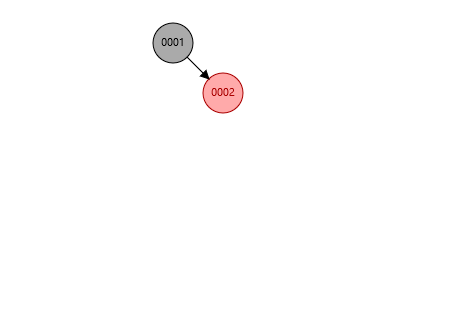
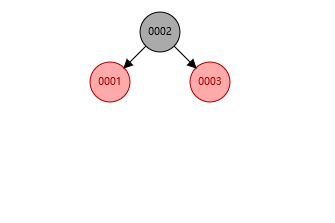
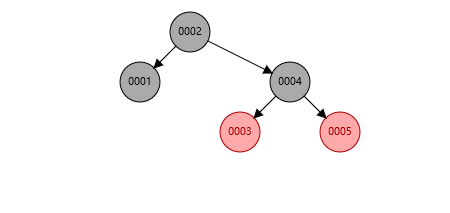
就像图片那样,当你一边子树过多时,他就会自动调整,但是如果数据过多还会存在问题,那就是树的深度太大,查找也会费时间
在这里我们引入B树。
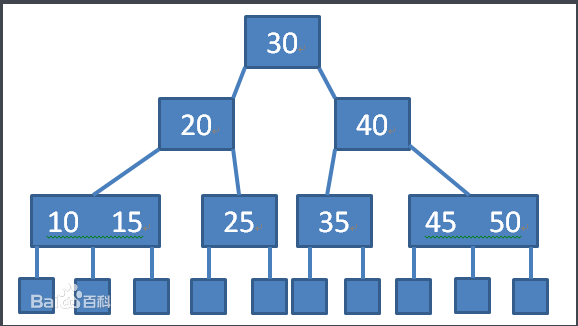
- 叶节点具有相同的深度,叶节点的指针为空
- 所有索引元素不重复
- 节点中的数据索引从左到右依次递增排列
但在数据库中实际用到的是B+树,根据B树更改的一种数据结构
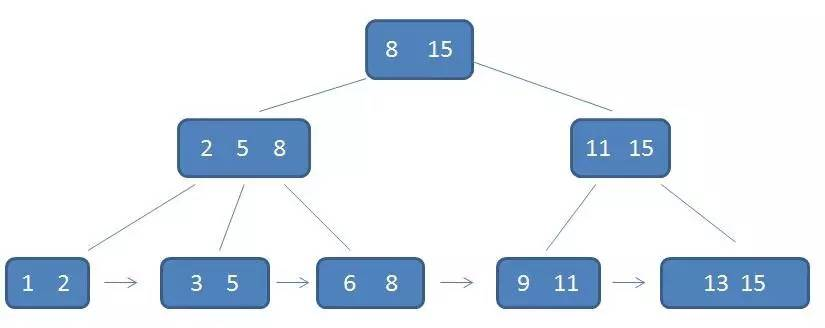
B+树特征
非叶子结点不存储data,只存储索引(冗余),可以放更多的索引
叶子结点包含所有索引字段
叶子结点用指针连接,提高区间访问性能
具体请访问https://www.jianshu.com/p/71700a464e97
Hash索引
在理想的情况下,key非常分散,不存在Hash碰撞的话,采用Hash索引可以唯一得确定一个key的位置,并且这个位置上就只有一个key,所以查找时间复杂度是O(1),非常快,这是Hash索引的最主要优势。但是呢,Hash索引不是没有缺点,不存在Hash碰撞这是理想情况,通常情况下,同一个Hash值都不只有一个key,也就是说你根据一个key找到了他的hash值位置之后,但是这个位置还有别的key,所以你还得从这个位置找到真正的key,至于怎么找,这个和具体的hash碰撞处理方式有关,最常用的扩展链表法,就是在hash位置上放置链表,此时,就存在一个链表查询的过程,如果hash碰撞比较严重,查询的时间复杂度就远不止O(1),那么hash索引的优势就失去了。其次,Hash索引是不排序的,因此它只适用于等值查询,如果你要查询一定的范围内的数据,那么hash索引是无能为力的,只能把数据挨个查,而不能仅仅是查询到头尾数据之后,从头读到位。并且,hash索引也无法根据索引完成排序,这也是它的不足之一。
而B+树是一颗严格平衡搜索的树,从根节点到达每一个叶子节点的路径长度都是一样的,并且每个节点可以有多个孩子节点(高扇出),所以可以进可能的把树的高度降到很低。这么做的好处是可以降低读取节点的次数,这就是的B+树非常适合做外部文件索引了。在外部文件索引中,必须要读取到一个节点之后,才能知道它所有的孩子几点的位置,而读取一个节点对应一次IO,所以读取叶子节点的IO数就等于树的高度了,因此树的高度越低,所需要的IO次数就越少。B+树是一颗搜索树,所有的数据都放在叶子节点上,并且这些数据是按顺序排列的。所以在范围查询中,只需要找到范围的上下界节点,就可以得到整个范围内的数据,而且还有一个好处,由于这些数据都是排好序的,所以无需对数据进行再次排序。
总结:
1.Hash索引在不存在hash碰撞的情况下,之需一次读取,查询复杂度为O(1),比B+树快。
2.但是Hash索引是无序的,所以只适用于等值查询,而不能用于范围查询,自然也不具备排序性。根据hash索引查询出来的数据,还有再次进行排序
3.B+树索引的复杂度等于树的高度,一般为3-5次IO。但是B+树叶子节点上的数据是排过序的,因此可以作用于范围查找,而且查询的数据是排过序的,无需再次排序。对于像“SELECT xxx FROM TABLE1 WHERE xxx LIKE ‘aaa%’”这样涉及到模糊匹配的查询,本质上也是范围查询。
4.还有一点,数据库中的多列索引中,只能用B+树索引。数据在B+树的哪个结点上,只取决于最左边的列上的key,在结点中在一次按照第二列、第三列排序。所以B+树索引有最左原则的特性。