首先下面有一段最基本的hashmap操作的代码:
1 | package HashMaptest; |
输出结果:
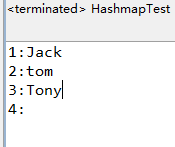
代码比较简单就是向hashmap中存放了4组值,可以看到允许插入空值,并且相同的key会覆盖(输出的是Jack而不是jack)然后遍历一遍hashmap(正好复习了一遍hashmap的4种遍历方法)。
1. hashmap简介
HashMap基于哈希表的Map接口实现,是以key-value存储形式存在。(除了不同步和允许使用 null 之外,HashMap 类与 Hashtable 大致相同。)
HashMap 的实现不是同步的,这意味着它不是线程安全的。它的key、value都可以为null。此外,HashMap中的映射不是有序的。在 JDK1.8 中,HashMap 是由 数组+链表+红黑树构成,新增了红黑树作为底层数据结构,结构变得复杂了,但是效率也变的更高效。
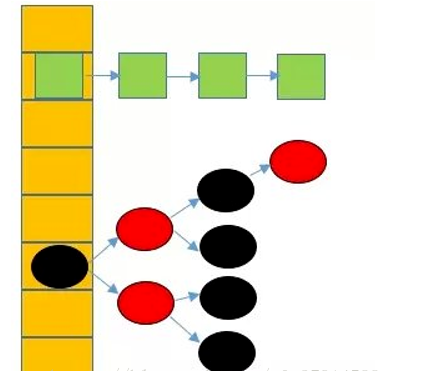
哈希桶就是数组里面的一个位置中所占所有数据,例如,下图中,绿色节点所占的该数组的位置,以及它连接的链表,整体为一个哈希桶。
2.属性
我们直接来看源码
1 | public class HashMap<K,V> extends AbstractMap<K,V> |
在这里说一下加载因子
何为加载因子?
加载因子是表示Hsah表中元素的填满的程度.若:加载因子越大,填满的元素越多,好处是,空间利用率高了,但:冲突的机会加大了.反之,加载因子越小,填满的元素越少,好处是:冲突的机会减小了,但:空间浪费多了.
冲突的机会越大,则查找的成本越高.反之,查找的成本越小.因而,查找时间就越小.
因此,必须在 “冲突的机会”与”空间利用率”之间寻找一种平衡与折衷. 这种平衡与折衷本质上是数据结构中有名的”时-空”矛盾的平衡与折衷.
HashMap默认的加载因子是0.75,最大容量是16,因此可以得出HashMap的默认容量是:0.75*16=12。
用户可以自定义最大容量和加载因子。
3.构造方法
hashmap一共有4种构造法
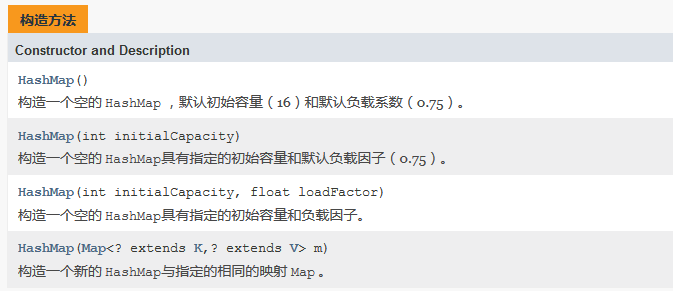
源码如下:
1 | public HashMap() { |
第一个,空参构造,使用默认的加载因子0.75;
第二个,设置初始容量,并使用默认的加载因子;
第三个,设置初始容量和加载因子,其实第二个构造方法也是调用了第三个。下面,在看看最后一个构造函数。
1 | public HashMap(Map<? extends K, ? extends V> m) { |
该构造函数,传入一个Map,然后把该Map转为hashMap,resize方法在下面添加元素的时候会详细讲解,在上面中entrySet方法会返回一个Set<Map.Entry<K, V>>,泛型为Map的内部类Entry,它是一个存放key-value的实例,也就是Map中的每一个key-value就是一个Entry实例,为什么使用这个方式进行遍历,因为效率高,具体自己百度一波,putVal方法把取出来的每个key-value存入到hashMap中,待会会仔细讲解。
构造函数和属性讲得差不多了,下面要讲解的是增删改查的操作以及常用的、重要的方法,毕竟里面的方法太多了,其它的就自己去看看吧。
4.添加元素
添加元素也就是put()方法,在讲解put之前我们要看看hash方法如何计算哈希值的
1 | static final int hash(Object key) { |
接下来看put方法。
1 | public V put(K key, V value) { |
上面就是具体的元素添加,在元素添加里面涉及到扩容,我们来看看扩容方法resize。
1 | final Node<K,V>[] resize() { |
5.删除
1 | public V remove(Object key) { |
删除还有clear方法,把所有的数组下标元素都置位null,下面在来看看较为简单的获取元素与修改元素操作。
6.获取元素:
1 | public V get(Object key) { |
7.修改元素
元素的修改也是put方法,因为key是唯一的,所以修改元素,是把新值覆盖旧值。
原文链接:https://blog.csdn.net/m0_37914588/article/details/82287191